
[Paper Review] LLaMA: Open and Efficient Foundation Language Models
What are Large Languages Models (LLMs)?
Recently, Large Languages Models (LLMs) have been a big game changer in various fields, e.g., industry, social media, education, and entertainment. Since OpenAI announced the ChatGPT, big techs have tried to develop their own LLMs; meanwhile, startups have deeply searched for a way to employ their API for a specific service.
LLMs are trained on massive amounts of text data for billions of parameters to achieve generalized language understanding and generation, thus, their training costs are super expensive. LLMs mainly consist of transformers and are trained in a self-driven or semi-supervised manner. Through the series of posts, I will start my journey to technically understand recent LLMs (most of them will be from big techs) or NLP.
LLaMA
LLaMA is a model released by Meta at 2023. LLaMA successfully achieved competitive performances compared to the existing LLMs such as GPT-3, Chinchilla, and PaLM with smaller parameters ranging from 7B to 65B. There are several advantages to using LLaMA: (1) The model can be run on a single GPU. (2) The model is trained by only publicly available benchmarks that can lead to high-compatibility of open-source research. Therefore, LLaMA is now widely employed in most language model applications on open-source communities, like Hugging Face or Github.
Inference Budgets are Critical.
Hoffmann et al., 2022 [1] explored optimal model sizes according to the amounts of the dataset at a training level. However, LLaMA pointed out that inference budgets are also crucial from a service-wise perspective, since [1] only computed training costs. The authors asserted as follows:
“To train a smaller model longer with more datasets leads to a cheaper cost of text generation.”
Methods
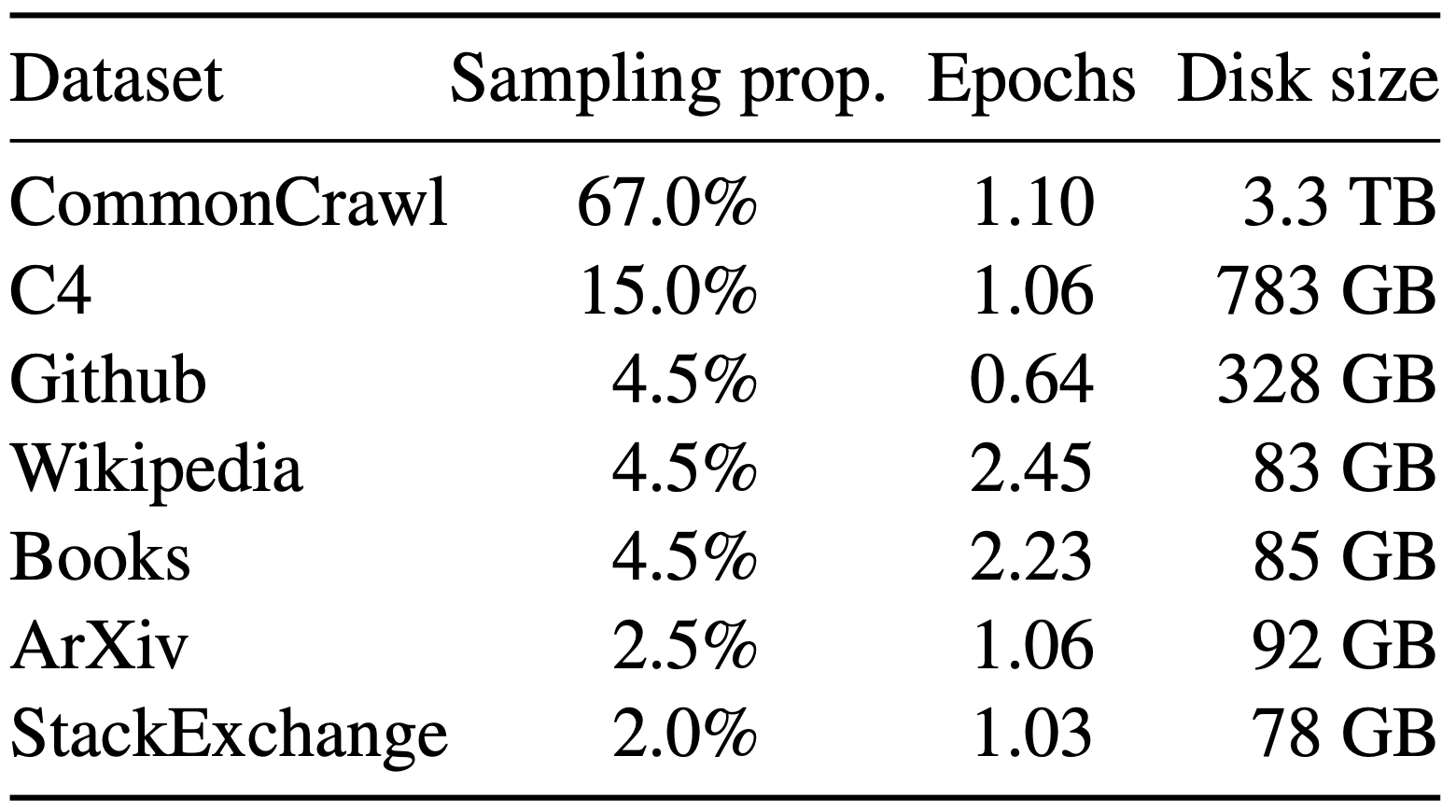
-
Datasets The authors utilized publicily avaliable datasets as shown in the table.
-
Architecture Refer to recent LLMs, they employed pre-normalization (GPT-3) for training stability, SwiGLU activation function [2] (PaLM), and rotary positional embeddings (RoPE) [3].
-
Efficient implementation I think this part is a key idea to save training costs; (1) causal multi-head attention (xformers library), (2) store activations and re-use them during backward propagation, (3) model and sequence parallelism (see [4]), and (4) overlap the computation of activations and the communication between GPUs over the network.
Evaluations
To evaluate LLMs, there are several tasks and benchmarks.
(1) Common Sense Reasoning
- Benchmarks BoolQ, PIQA, SIQA, HellaSwag, WinoGrande, ARC easy and challenge, and OpenBookQA
(2) Closed-book Question Answering
- Benchmarks Natural Questions and TriviaQA
(3) Reading Comprehension
- Benchmark RACE
(4) Mathematical Reasoning
(5) Code Generation
(6) Massive Multitask Language Understanding
- Benchmark MMLU
(7) Bias, Toxicity and Misinformation
The following benchmarks are useful to check whether LLMs are toxic, biased, and misinformative.
- Benchmarks RealToxicityPrompts, CrowS-Pairs, and TruthfulQA
Conclusion
LLaMA-1 improved its performance by combining various recent works and found a way to argue their novelty from open sourcing. By aggressively leveraging open-source benchmarks, this paper provided a standard for analyzing LLMs to some extent, e.g., various benchmarks and evaluation metrics.
References
[1] Hoffmann, Jordan, et al. “Training compute-optimal large language models.” arXiv preprint arXiv:2203.15556 (2022).
[2] Shazeer, Noam. “Glu variants improve transformer.” arXiv preprint arXiv:2002.05202 (2020).
[3] Su, Jianlin, et al. “Roformer: Enhanced transformer with rotary position embedding.” Neurocomputing (2023): 127063.
[4] Korthikanti, Vijay Anand, et al. “Reducing activation recomputation in large transformer models.” Proceedings of Machine Learning and Systems 5 (2023).