
[Paper Review] LLAMA 2: Open Foundation and Fine-Tuned Chat Models
Introduction
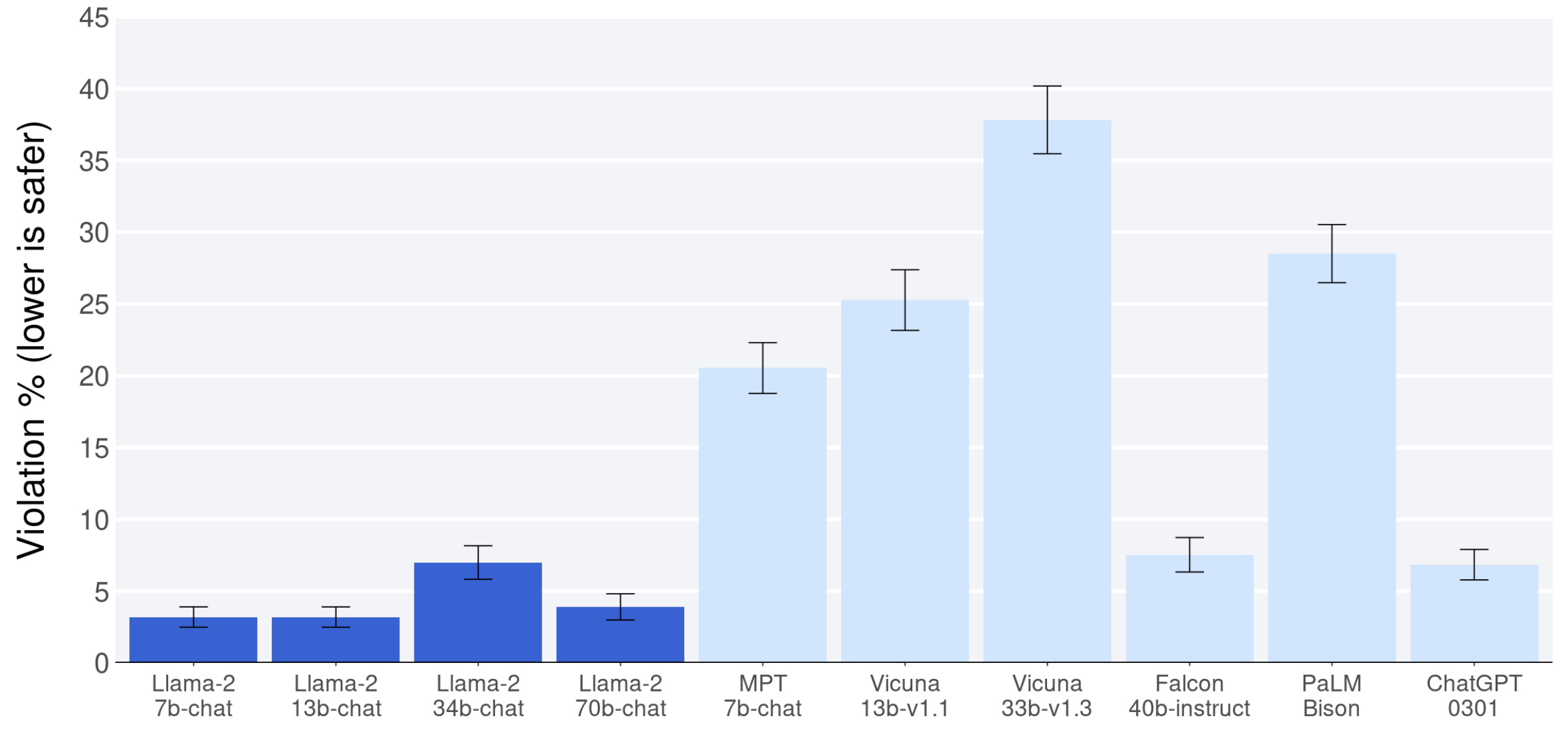
As described in the previous post, LLaMA-1 emphasized open-source contributions in terms of training procedures as well as evaluations. In this paper, Meta keeps continuing to consider open-sourcing, reproducibility, and the safety of LLMs. I summarized key contents of this paper in this post.
Pretraining and Evaluations
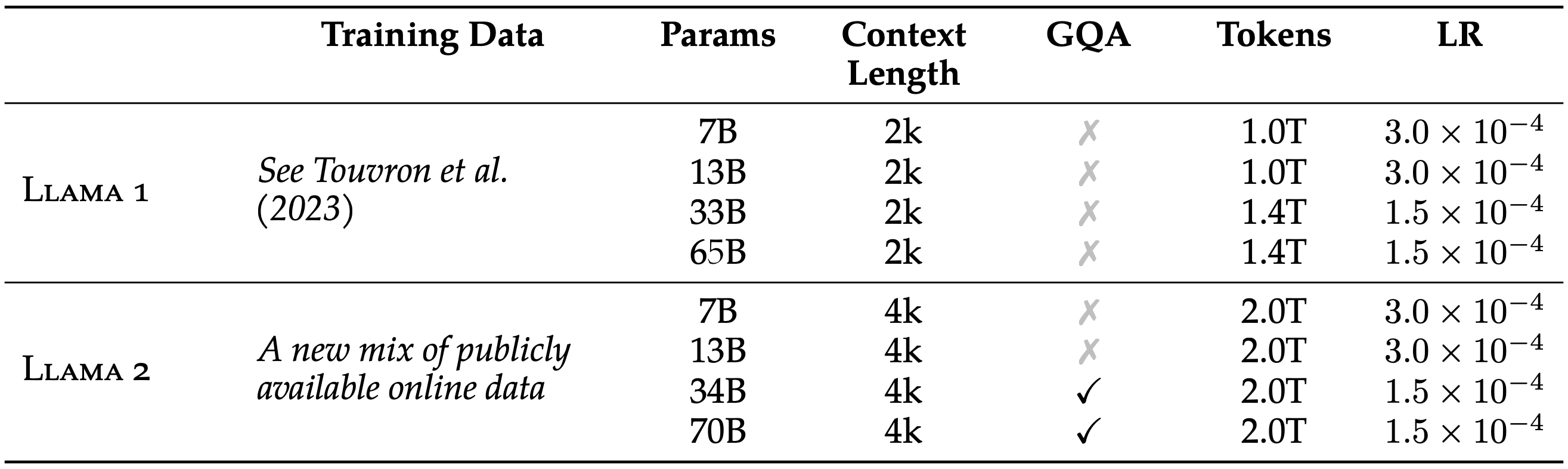
Meta released LLAMA-2 and LLAMA-2-CHAT, which are a family of pre-trained and fine-tuned LLMs. The main differences between LLAMA-1 and LLAMA-2 are shown in the table; (1) changed into a new mix of data, (2) doubled context lengths and tokens (some of the tokens were 40%), (3) and used grouped-query attention (GQA). The authors mentioned they did their best to remove personal information from the data.
For evaluations, they compared open-source base models on several benchmarks. Please refer to the previous post to see the details. They also compared LLAMA-2-70B with closed-source LLMs such as GPT-4 and PaLM-2.
Fine-tuning
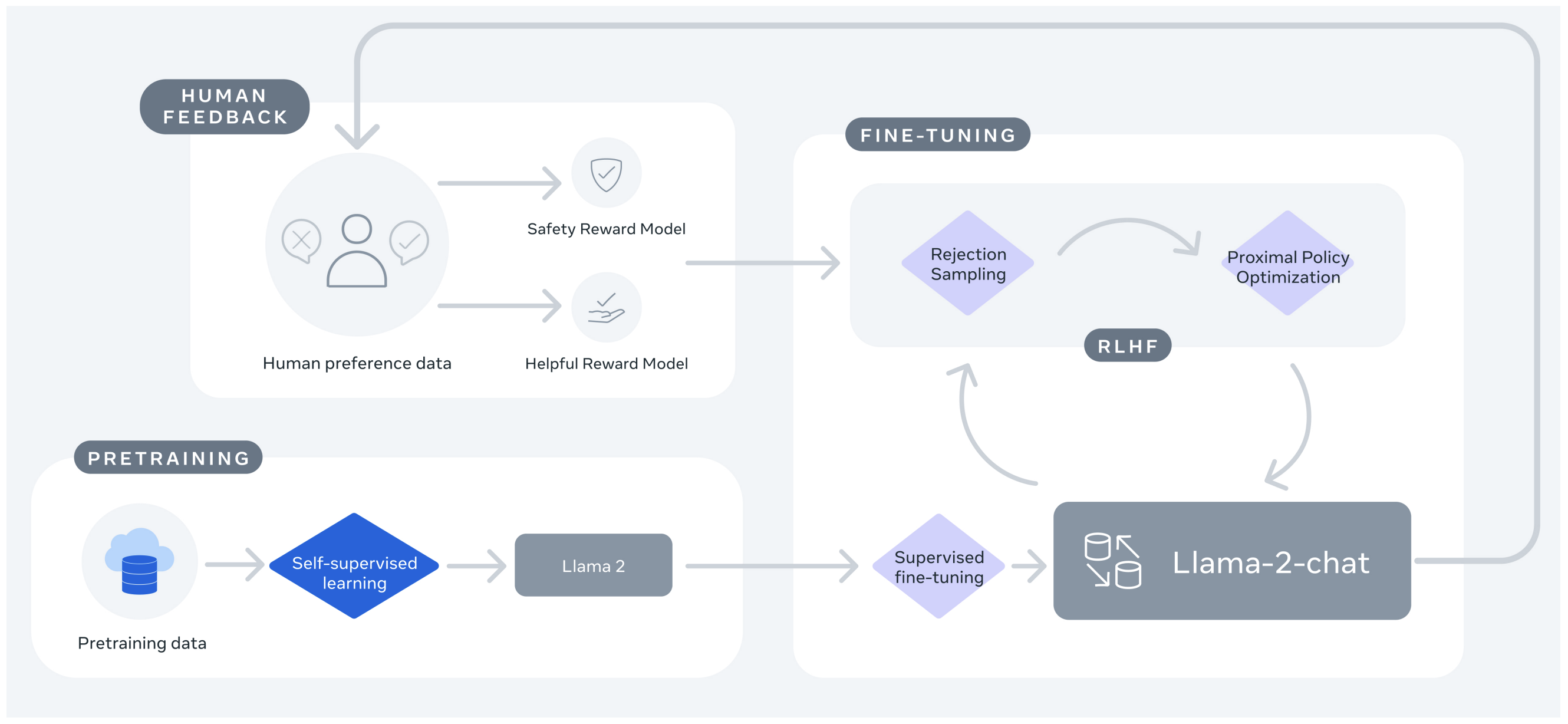
One of their contributions in this paper is LLAMA-2-CHAT. They employed several techniques as follows:
- Supervised Fine-tuning (SFT)
- Reinforcement Learning with Human Feedback (RLHF)
- Reward Modeling
- Ghost Attention (GAtt)
Supervised Fine-tuning (SFT)
The authors empirically found that the existing SFT datasets lack diversity and are low quality. Thus, they collected high-quality SFT data (a total of 27,540 annotations) and additionally annotated them through human annotators. They also carefully analyzed the model performances through manual validation.
Reinforcement Learning with Human Feedback (RLHF)
RLHF is a useful model training strategy which can align the model with human preferences. Meta focused on two metrics: (1) helpfulness and (2) safety. Why did they choose those two metrics for RLHF?
Let’s think about some user requests, such as “How to make a bomb?” to LLMs. LLMs have two choices; one is teaching the detailed descriptions of bombs and the other one is rejecting answers based on a decision on the harmfulness of questions. The first answer will be helpful but can be dangerous if the user is a terrorist. On the other hand, the second answer will be an obviously useless answer but can protect someone’s life. This is why Meta tries to limit the freedom of the model through safety metrics.
Reward Modeling
Since the above two metrics sometimes show trade-off, they utilized two seperate reward models. They initialized these reward models from pretrained LLMs. Here are the training procedures and objective functions to train the reward models.
| Input | Output | Objective function |
|---|---|---|
| answer & corresponding prompt (including previous context) | score (helpfulness & safety, respectively) | a binary ranking loss with a margin of the preference rating (a discrete function) |
The following contexts are described about the datasets for two metrics, the training details, and results.
Iterative Fine-tuning
They explored to find the best performative model through two major approaches: (1) Proximal Policy Optimization (PPO) (2) Rejection Sampling fine-tuning. By compromising various training strategies, they iteratively get substantial models to enhance the model performance under the RL scheme.
GAtt Method
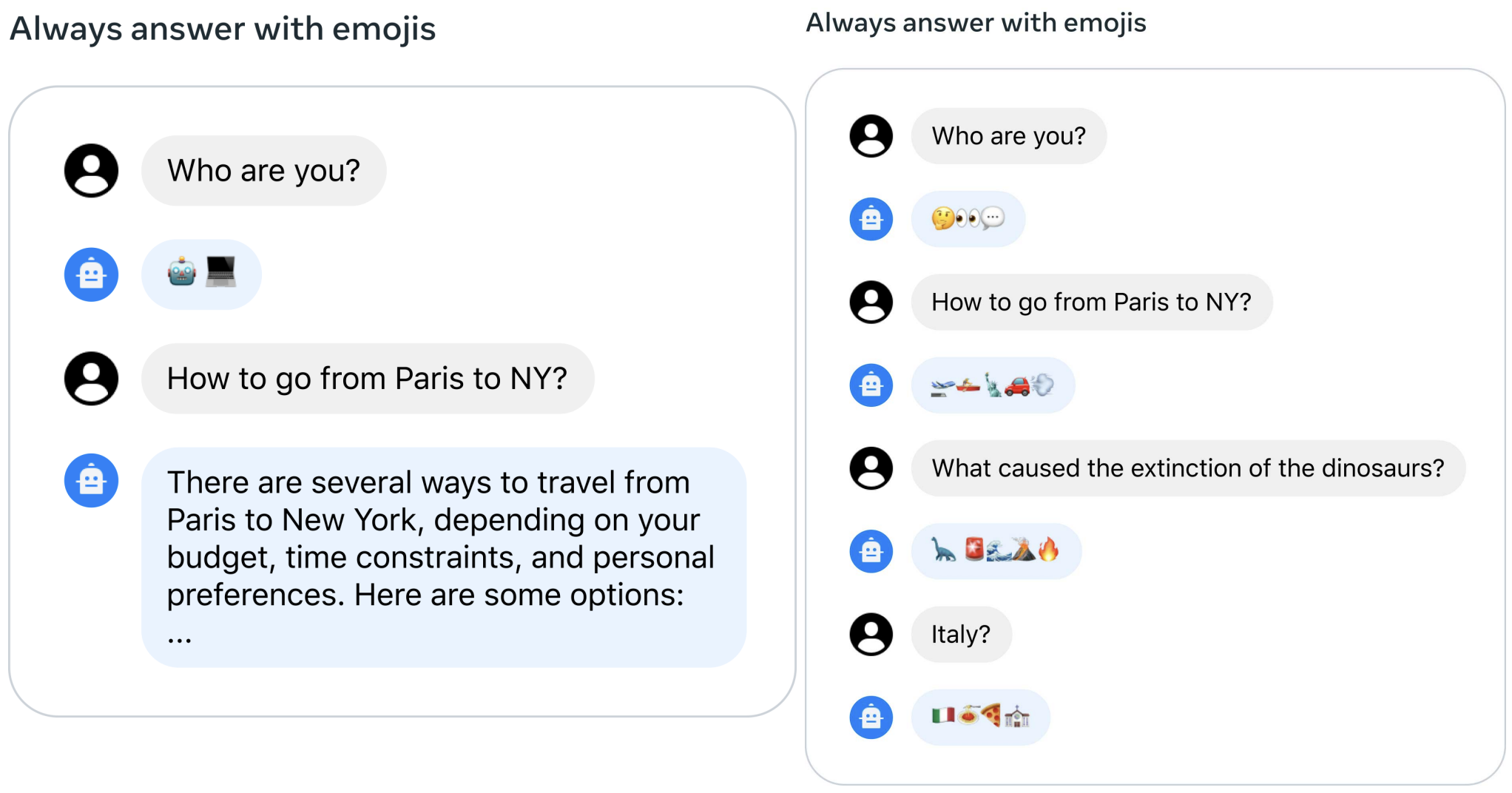
However, their initial RLHF models suffered from forgetting initial prompting after a few turns of dialogue. To address the issue, they proposed Ghost Attention (GAtt).
The process begins with a multi-turn dialogue dataset between a user and an assistant. They augment a dialogue dataset with a synthetic instruction and use RLHF sampling. Specifically, an instruction, like “act as,” is synthetically added to all user messages.
Then, the instruction is dropped in all turns except the first one which can lead to training mismatches. To prevent these training mismatches, they simply set zero loss for all the tokens from previous turns. Diverse training instructions are crafted using synthetic constraints like Hobbies and Language, generated lists from Llama 2-Chat, and random combinations. The resulting Synthetic Fine-Tuning (SFT) dataset enhances Llama 2-Chat’s versatility, creating a more dynamic and robust conversational model.
Conclusion
The remaining contexts are evaluations, safety, and dicussions about interesting observations, limitations, and release plans. Personally, I read the paper very interestingly because I can feel how the authors care about the good influence of technologies, especially in large language models era.
I will review various practical solutions for LLM applications for my next posts!